Um Data Lake é um repositório central de dados, responsável por ingerir fontes distintas, tratar os dados e catalogar para habilitar a conexão de uma camada analítica e de IA. O armazenamento dos dados é segmentado em 3 camadas:
Bronze: camada de dados puros, na forma que são ingeridos de suas fontes. Esse dado é mantido para a possibilidade de reconstrução de estruturas de dados caso necessário!
Silver: camada de dados tratados por regras de limpeza. Nessa camada o dado já é catalogado e está próprio para consumo ad-hoc por meio de query SQL.
Gold: camada de dados analíticos, transformados e enriquecidos por meio de ETL (extract transform and load). Aqui temos o dado já montado para visualização analítica em ferramentas de BI (business intelligence) ou por IA.
CONTEXTO
Quando usar um Data Lake?
O Data Lake é a estrutura indicada para empresas que querem cruzar dados de fontes separadas de forma estruturada e eficiente. Ou seja, caso exista a necessidade de incorporar dados corporativos complexos em visualizações de BI ou relatórios executivos, o Data Lake é a estrutura ideal para resolver o desafio. Finalmente, o Data Lake é aplicável também para o offload de bases transacionais que possuem alta carga de visualização atrelada, ou seja, reduzir consumo em read replicas de bancos transacionais.
SOLUÇÃO
Arquitetura de um Data Lake
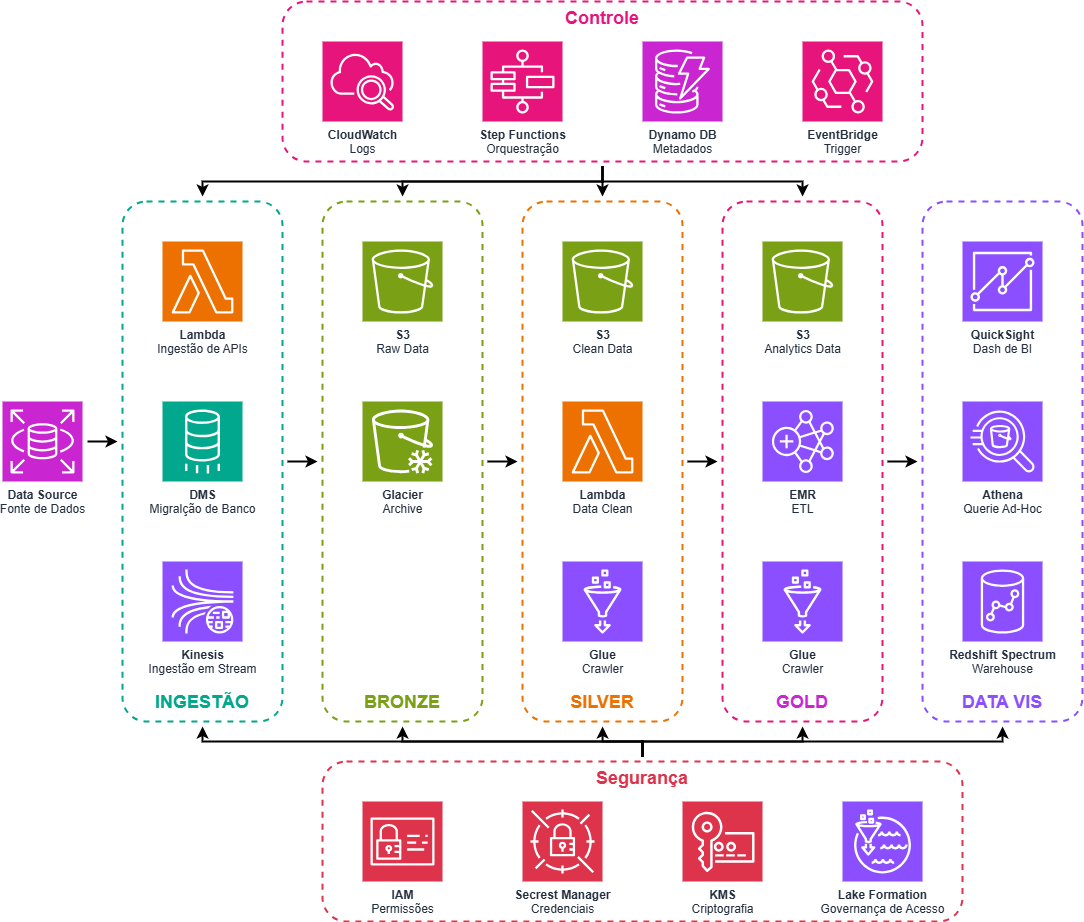
A figura abaixo ilustra um escopo macro do Data Lake:
Fonte de dados: a fonte de origem dos dados, que pode ser uma base relacional, API, stream de dados, dados semi-estruturados, dados não estruturados, etc.
Ingestão: a camada responsável por trazer os dados de suas fontes para a AWS, podendo usar de funções Lambda, Database Migration Service (DMS), família Kinesis ou similares.
Bronze: armazenamento dos dados brutos no S3, podendo se beneficiar de armazenamentos frios como o Glacier.
Silver: camada de limpeza de dados via Lambda ou similares, armazenamento no S3 e catalogação via Glue.
Gold: camada de enriquecimento e transformação dos dados por meio de Elastic Map Reduce (EMR), armazenamento no S3 e catalogação no Glue.
Data Vis: consumo analítico dos dados do Lake, seja por BI com QuickSight, query SQL pelo Athena ou warehousing para demandas complexas pelo Redshift.
Controle: essa é a camada de gestão dos serviços, onde os logs são visualizados no CloudWatch, os demais serviços são orquestrados no StepFunctions, os metadados do Lake são registrados no DynamoDB e o disparo dos processos é feito no EventBridge.
Segurança: serviços responsáveis por controle de acesso dos recursos no IAM (Identity and Access Manager), criptografia no KMS (Key Management Service) e governança de acessos de usuário pelo Lake Formation.
REQUISITOS
O que preciso ter para começar?
Para começar a desenvolver o seu Data Lake na Lascasas Consulting é simples! Separe:
Fontes de dados a serem usadas;
Acessos aos dados (usuários de banco, cofre de senhas, chaves de API, etc);
Acesso à conta AWS para implantação do Data Lake;
Repositório Git para o Data Lake;
Documentações relevantes de tratamento de dados (scripts, queries, PDF, etc);
Visualização em dashboard desejada para o projeto.
MODUS OPERANDI
Como é o projeto de Data Lake?
No projeto do Data Lake, iremos construir uma esteira de CI/CD para entrega do Data Lake como código. Assim, o primeiro passo é a fundação da estrutura. Em seguida, uma carga histórica é feita nos dados para construção dos processos analíticos. Com os dados carregados, os mesmos são limpos, transformados e enriquecidos nas 3 camadas do Lake. Finalmente, o dashboard é montado e o gatilho de atualização de dados é habilitado.
PRÓXIMOS PASSOS
Como iniciar meu projeto?
Leia mais sobre um estudo de caso da estrutura de Data Lake na AWS: