Introdução de Negócio
Empresas geram volumes cada vez maiores de dados provenientes de aplicações digitais, sistemas transacionais, dispositivos IoT e interações com clientes. No entanto, muitas organizações ainda enfrentam dificuldades para consolidar essas informações em um ambiente único que permita análise eficiente e geração de insights de negócio. Sem uma arquitetura adequada, os dados acabam fragmentados em diferentes sistemas, dificultando análises avançadas, iniciativas de inteligência artificial e a criação de dashboards estratégicos para tomada de decisão.
O que queremos resolver
Um dos maiores desafios para empresas orientadas a dados é lidar com a diversidade de fontes e formatos de informação. Dados podem chegar em tempo real através de streams, serem extraídos de bancos de dados operacionais ou originar de APIs externas. Esses dados frequentemente passam por múltiplos processos manuais de transformação, o que aumenta a complexidade operacional e gera inconsistências. Além disso, a falta de governança e controle de acesso pode criar riscos de segurança e dificultar o uso dos dados por diferentes áreas da empresa. Finalmente, em uma era de IA, sabemos que a qualidade de dados reflete diretamente na qualidade dos resultados de modelos de IA.
Como resolver na AWS
Uma arquitetura de Data Lake na AWS permite centralizar dados de diferentes origens em um ambiente escalável, seguro e preparado para análises avançadas.
O processo começa com a camada de ingestão, onde dados são capturados de diversas fontes. Integrações podem ser realizadas via AWS Lambda para ingestão de APIs, AWS Data Migration Service para migração de dados de bancos relacionais e Amazon Kinesis para ingestão de eventos em tempo real.
Esses dados são armazenados inicialmente na zona RAW do data lake, utilizando Amazon S3 como repositório central de armazenamento. Essa camada preserva os dados em seu formato original, garantindo histórico completo e permitindo reprocessamentos futuros quando necessário.
Na sequência, pipelines de transformação organizam os dados na camada CLEAN, onde são padronizados, enriquecidos e catalogados. Processos de transformação podem ser executados com AWS Lambda ou frameworks de processamento distribuído como Amazon EMR, enquanto AWS Glue realiza o catálogo e descoberta automática de metadados. Após transformações mais complexas, os dados são disponibilizados na camada ANALYTICS, otimizada para consultas analíticas e workloads de inteligência de dados.
Por fim, ferramentas de consumo permitem que diferentes áreas da empresa explorem os dados. Consultas ad hoc podem ser executadas com Amazon Athena, enquanto dashboards e visualizações de negócio podem ser construídos no Amazon QuickSight.
Todo o ambiente é complementado por uma camada de governança e controle, incluindo AWS IAM para controle de acesso, AWS KMS para criptografia e AWS Lake Formation para gestão centralizada de permissões no data lake.
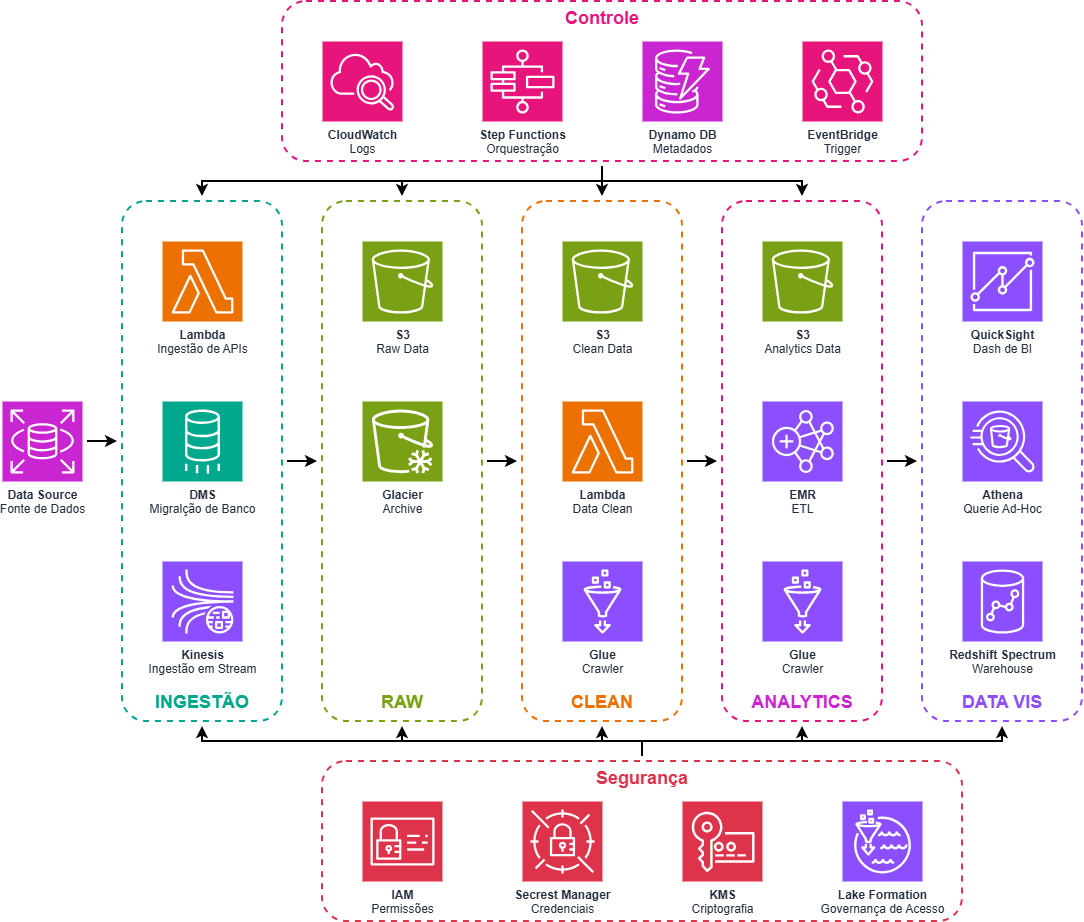
A figura acima representa de forma simplificada essa arquitetura AWS para a solução de Data Lake Serverless.
Ganhos que a arquitetura traz
Escalabilidade praticamente ilimitada: O uso do Amazon S3 permite armazenar petabytes de dados com alta durabilidade e baixo custo. Essa escalabilidade é nativa e intrínseca do próprio serviço, sem necessidade de aquisições antecipadas ou provisionamento de recursos.
Flexibilidade para diferentes tipos de dados: A arquitetura suporta dados estruturados, semi-estruturados e não estruturados, centralizando todos em um formato estruturado para soluções de IA e analytics.
Processamento sob demanda: Ao utilizar ferramentas primariamente serverless, a arquitetura de Data Lake é altamente escalável e o custo é gerido por demanda, sem necessidade de provisionamento de infraestruturas tradicionais.
Governança e segurança integradas: Serviços como Lake Formation e IAM garantem controle granular de acesso aos dados, democratizando com segurança os dados sensíveis da empresa para soluções ou personas que precisam desse nível de acesso sem abrir portas para riscos de data leak.
Base para iniciativas de IA e analytics avançado: Um data lake estruturado permite acelerar projetos de machine learning, BI e análise preditiva.
Casos na literatura
A adoção de arquiteturas modernas de dados pode gerar impactos significativos na velocidade de geração de insights. Estudos da Gartner indicam que 70% das organizações modernas adotarão soluções de dados para suporte de IA até 2027. Essas soluções de IA vão acelerar eficiência de dados em 40% para as empresas preparadas.
Casos de clientes da AWS demonstram benefícios concretos. Empresas como a FINRA utilizam data lakes na AWS para processar dezenas de bilhões de eventos de mercado diariamente, permitindo monitoramento e análise em larga escala.
Outro exemplo é a Zalando, que utiliza uma arquitetura baseada em data lake para democratizar o acesso a dados em toda a organização, permitindo que diferentes equipes tomem decisões baseadas em analytics avançado.
Lições aprendidas
Arquiteturas de Data Lake representam um passo fundamental para empresas que desejam se tornar verdadeiramente orientadas a dados. Ao combinar armazenamento escalável, pipelines de processamento e ferramentas analíticas integradas, a AWS permite construir plataformas de dados capazes de suportar desde dashboards operacionais até aplicações avançadas de inteligência artificial. Com uma base sólida de dados, organizações conseguem acelerar a geração de insights, melhorar processos de negócio e criar novas oportunidades de inovação baseada em dados.