O que é RAG?
Modelos de linguagem de grande porte (LLMs) são treinados com enormes volumes de dados, mas carregam três limitações estruturais: seu conhecimento é estático (limitado à data de corte do treinamento), eles não têm acesso a dados privados da sua organização, e estão sujeitos a alucinações.
Retrieval-Augmented Generation (RAG) é uma arquitetura que resolve essas três limitações ao mesmo tempo. A ideia é direta: antes de gerar uma resposta, o sistema recupera documentos relevantes de uma base de conhecimento e os injeta no contexto da pergunta. Assim, o modelo passa a raciocinar sobre informação atual, privada e verificável, não apenas sobre o que memorizou durante o treinamento.
O conceito foi formalizado no paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis et al., 2020), e foi com base nessa nova tecnologia que a AWS desenvolveu mecanismos de utilização dessa ferramenta como um serviço em seu catálogo. Dessa maneira, serviços como o Opensearch, Bedrock, S3 Vectors, dentre outros, sustentam a utilização de RAG na AWS.
Apesar de ser uma tecnologia consolidada ao longo dos anos, existem desafios na construção de uma arquitetura resiliente para RAG. Este artigo cobre toda a pilha técnica: desde a ingestão de documentos e estratégias de chunking até as abordagens avançadas de retrieval, modelos de embedding, opções de vector store na AWS e como medir a qualidade do sistema com rigor.
Os dois pipelines de um sistema RAG
Um sistema RAG opera com dois pipelines distintos que precisam ser projetados separadamente:
Pipeline de ingestão (offline): processa documentos em lote ou de forma incremental. Os documentos são carregados de uma fonte (tipicamente Amazon S3), divididos em chunks, convertidos em vetores de embedding por um modelo e armazenados em uma vector store junto com seus metadados.
Pipeline de inferência (online): responde perguntas em tempo real. A query do usuário é convertida no mesmo espaço vetorial do pipeline de ingestão, uma busca por similaridade retorna os K chunks mais relevantes, e esses chunks são concatenados ao prompt enviado ao LLM. A resposta gerada é então devolvida ao usuário com as fontes referenciadas.
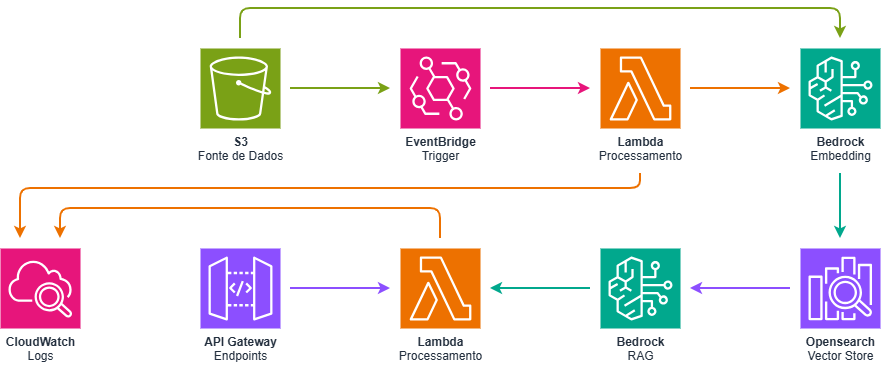
Na AWS, o mapeamento de componentes fica assim:
Técnicas para aprimorar o RAG
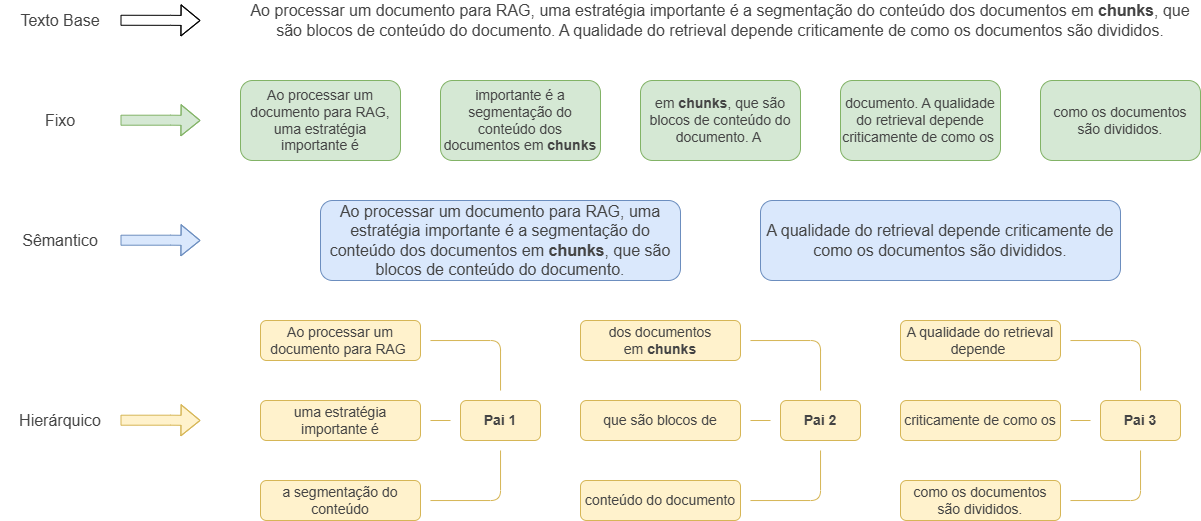
Ao processar um documento para RAG, uma estratégia importante é a segmentação do conteúdo dos documentos em chunks, que são blocos de conteúdo do documento. A qualidade do retrieval depende criticamente de como os documentos são divididos. Um chunk muito grande carrega ruído excessivo e desperdiça janela de contexto do LLM; um chunk muito pequeno perde o contexto local necessário para a resposta fazer sentido. Não existe bala de prata! A escolha da melhor estratégia depende do tipo de documento e da natureza das perguntas que o sistema precisa responder.
As três principais estratégias de chunking são:
Tão importante quanto a estratégia é o enriquecimento com metadados. Cada chunk deve carregar atributos como fonte do documento, data de criação, categoria, departamento ou nível de acesso. Metadados bem definidos permitem filtragem antes ou depois da busca vetorial, reduzindo o escopo e melhorando drasticamente a precisão. É muito importante definir o schema de metadados antes de indexar, porque adicioná-los depois exige re-ingestão completa.
Para documentos não textuais (PDFs escaneados, imagens), o Amazon Textract extrai texto estruturado, incluindo tabelas e formulários, antes do pipeline de chunking. O Amazon Bedrock Knowledge Bases automatiza toda essa etapa com conectores nativos para S3, SharePoint, Confluence, Salesforce e páginas web via crawling.
Modelos, técnicas e trade-offs
Embeddings são representações numéricas densas de texto em um espaço vetorial de alta dimensão. Textos semanticamente similares ficam próximos nesse espaço, permitindo que a busca por similaridade recupere chunks relevantes mesmo quando a pergunta usa vocabulário diferente do documento.
A AWS oferece dois modelos de embedding nativos via Amazon Bedrock:
Além da escolha do modelo, três técnicas avançadas podem aumentar significativamente a qualidade dos embeddings:
Um ponto crítico de operação: o modelo de embedding usado na ingestão e o usado nas queries precisam ser exatamente o mesmo. Trocar de modelo implica re-indexar toda a base de dados, porque os vetores novos e os antigos vivem em espaços incompatíveis, gerando similaridades não representativas. Versionize o modelo como parte da configuração do sistema.
Além da busca semântica simples
A busca semântica por similaridade de cosseno é o ponto de partida, mas raramente é suficiente para produção. As técnicas abaixo elevam significativamente a qualidade do retrieval:
Hybrid Search (BM25 + Semântico): combina a força da busca lexical BM25 com a busca semântica. BM25 é preciso para termos técnicos, siglas, nomes de produtos e consultas literais, exatamente onde modelos densos costumam falhar. O OpenSearch Serverless implementa essa combinação com um pipeline de normalização de scores (min-max ou L2) e métodos de combinação (média aritmética, geométrica ou harmônica). Em benchmarks de QA sobre domínios especializados, hybrid search supera consistentemente a busca puramente semântica.
Re-ranking: após o retrieval inicial (que retorna top-K chunks com base em velocidade), um modelo de re-ranking mais preciso reordena os resultados. O re-ranker analisa cada par (query, chunk) em conjunto, capturando nuances de relevância que o embedding de busca ignora por tratar query e documentos de forma separada. O Bedrock Knowledge Bases suporta re-ranking nativo com modelos da Amazon e Cohere.
Query Expansion: o LLM gera variações da query original antes da busca. Útil quando o usuário usa vocabulário diferente do documento ou quando a pergunta é ambígua. Aumenta recall ao custo de uma chamada LLM adicional antes do retrieval.
HyDE (Hypothetical Document Embeddings): em vez de buscar diretamente com o embedding da query, o LLM gera um documento hipotético que responderia à pergunta, esse documento é vetorizado para a busca. O vetor de um documento hipotético fica mais próximo dos vetores dos documentos reais do que o vetor da query original. Eficaz para perguntas abertas e sínteses, mas adiciona a latência de uma chamada LLM antes do retrieval.
Filtragem por metadados: restringe a busca vetorial a subconjuntos do índice com base em atributos (data, categoria, departamento, nível de acesso). Reduz o espaço de busca e evita que documentos irrelevantes contaminem o contexto do LLM. Todas as vector stores AWS suportam filtragem por metadados, a eficácia depende da qualidade com que esses atributos foram definidos na ingestão.
Comparativo e critérios de escolha
A vector store é o coração do pipeline de retrieval. A AWS oferece quatro opções nativas, cada uma com um perfil distinto de custo, latência e complexidade operacional:
Amazon S3 Vectors (documentação)
O serviço mais recente e o de menor custo: armazenamento de vetores diretamente no S3, com busca por similaridade nativa. Suporta até 2 bilhões de vetores por índice e 20 trilhões por bucket. A latência gira em torno de ~100ms para queries frequentes, o que não é a opção mais rápida, mas o custo de armazenamento é até 90% menor que soluções especializadas. Integra-se nativamente ao Bedrock Knowledge Bases, facilitando o processo de gestão. Indicado para alto volume de vetores com latência relaxada, cargas de trabalho de análise ou como tier de armazenamento frio em arquiteturas híbridas.
OpenSearch Serverless — Vector Search (documentação)
A opção mais completa para produção com requisitos avançados. Usa indexação HNSW via motor Faiss, suporta até 16.000 dimensões e três métricas de distância (Euclidiana, cosseno, produto interno). Escala compute units de ingestão e de query de forma independente. Sua grande vantagem é o suporte nativo a hybrid search (busca semântica combinada com BM25) via pipelines de normalização de score configuráveis. Note que os algoritmos IVF e IVFQ não estão disponíveis na versão Serverless (apenas no OpenSearch gerenciado).
pgvector no Amazon Aurora PostgreSQL (documentação)
A escolha natural quando a aplicação já usa Aurora ou RDS PostgreSQL. A extensão pgvector adiciona um tipo de coluna "vector" e suporte a índices HNSW diretamente no banco relacional. A principal vantagem é eliminar a necessidade de sincronizar um banco relacional (com metadados, usuários, entidades de negócio) com uma vector store separada. A versão 0.8.0 trouxe ganhos de até 9x na velocidade de query com índices HNSW.
Amazon MemoryDB — Vector Search (documentação)
Para quando latência sub-milissegundo é um requisito não-negociável. In-memory com durabilidade multi-AZ, suporta algoritmos FLAT (busca exata) e HNSW (aproximado), recall superior a 99%. Indicado para sistemas de recomendação em tempo real ou RAG com SLAs de resposta abaixo de 10ms. O custo por GB é significativamente maior que as demais opções, logo, reserve para casos onde a latência justifica o investimento.
| Latência típica | Escala máxima | Custo relativo | Hybrid Search nativo | Caso de uso ideal | |
|---|---|---|---|---|---|
| S3 Vectors | ~100ms | 20T vetores / bucket | Baixo | Não | Alto volume, latência relaxada |
| OpenSearch Serverless | Baixa | Alta | Médio | Sim (BM25 + semântico) | Produção avançada, hybrid search |
| pgvector (Aurora) | Baixa | Alta | Médio | Não nativo | Stack já usa PostgreSQL |
| MemoryDB | Sub-ms | Alta | Alto | Não | SLA crítico, tempo real |
A regra geral de escolha: comece com S3 Vectors se está prototipando ou tem alto volume com latência relaxada. Use pgvector se Aurora já está na stack e quer simplicidade operacional. Use OpenSearch Serverless para produção com hybrid search e requisitos de busca avançados. Reserve MemoryDB para os casos onde latência sub-ms é inegociável.
A solução gerenciada de RAG da AWS
O Amazon Bedrock Knowledge Bases é uma abstração gerenciada que automatiza o pipeline completo de RAG: ingestão, chunking, geração de embeddings, indexação na vector store e retrieval aumentado. Com poucos cliques (ou chamadas de API), você configura uma base de conhecimento sem precisar orquestrar cada componente manualmente.
O serviço suporta seis vector stores de destino: Aurora PostgreSQL, OpenSearch Serverless, Amazon S3 Vectors, Neptune Analytics, MongoDB Atlas e Pinecone. As estratégias de chunking disponíveis são fixo, semântico, hierárquico e Lambda customizado, este último para lógica de parsing proprietária, como documentos com estrutura muito específica. Os conectores de dados incluem S3, SharePoint, Confluence, Salesforce e páginas web via crawling nativo.
Para o retrieval, o Knowledge Bases expõe a API RetrieveAndGenerate que devolve a resposta do LLM já com as fontes citadas, sendo útil para auditoria e rastreabilidade. Também oferece re-ranking nativo e integração direta com o Amazon Bedrock Guardrails, que bloqueia inputs maliciosos (prompt injection), redacta PII e verifica se a resposta está ancorada no contexto recuperado (contextual grounding).
Quando usar Knowledge Bases ao invés de montar do zero: quando o time quer iterar rapidamente sem especialistas em ML para tunar o pipeline, e quando os conectores nativos cobrem as fontes de dados. A principal limitação é menor flexibilidade para estratégias customizadas... Se você precisa de HyDE, query expansion sofisticada ou lógica de re-ranking proprietária, provavelmente vai precisar de uma implementação própria combinando os primitivos (Bedrock embeddings + vector store direta + Lambda).
Como saber se o RAG está funcionando
Um dos erros mais comuns em projetos RAG é declarar sucesso sem um framework de avaliação quantitativo. Testar manualmente com dez perguntas não é uma avaliação de qualidade!
O RAGAS é o framework open-source de referência para avaliação de pipelines RAG. É reference-free, ou seja, não exige gabarito de respostas corretas para funcionar, e mede quatro dimensões independentes:
Na AWS, a instrumentação de observabilidade deve cobrir:
O loop de melhoria funciona assim: colete logs de produção → calcule métricas RAGAS sobre uma amostra → identifique o componente mais fraco (retrieval baixo Context Recall? Geração com baixo Faithfulness?) → intervenha cirurgicamente (ajuste chunking, troque modelo de embedding, adicione re-ranking, adicione guardrails) → re-meça. Sem esse ciclo, otimizações são cegas.
Checklist para produção
Comece medindo antes de tunar: antes de ajustar qualquer parâmetro, estabeleça uma baseline com métricas RAGAS. Otimizar chunking sem métricas é tentativa e erro.
Granularidade do chunk: comece com 512 tokens e overlap de 10%. Meça o Context Recall e ajuste. Chunks menores melhoram precisão; chunks maiores melhoram contexto. A granularidade ideal varia por tipo de documento, não use o mesmo valor para FAQs e contratos longos.
Metadados como cidadãos de primeira classe: defina o schema de metadados antes de indexar. Adicionar campos depois exige re-ingestão completa. Inclua pelo menos: fonte, data de criação/atualização, tipo de documento e nível de acesso.
Versionamento do modelo de embedding: documente e versionize o modelo de embedding usado. Uma atualização de modelo sem re-indexação quebra silenciosamente o retrieval. Trate o par (modelo, dimensões) como parte da configuração versionada do sistema.
Separação de ambientes: mantenha índices separados para dev, staging e produção. Nunca teste re-indexação em produção. A sincronização entre ambientes deve ser parte do pipeline de CI/CD.
Guardrails desde o início: configure o Bedrock Guardrails para bloquear prompt injection, redactar PII e verificar se a resposta está ancorada no contexto recuperado. O custo de adicionar guardrails após o go-live é significativamente maior.
Top-K adaptativo: não use K fixo para todos os casos. Perguntas factuais simples precisam de 3 a 5 chunks; perguntas de síntese podem precisar de 10 ou mais. Implemente lógica para variar K com base no tipo de query ou no score de confiança do retrieval.
Latência: o LLM é o gargalo, não o retrieval. Para reduzir latência total: use streaming de resposta do Bedrock (InvokeModelWithResponseStream), prefira chunks menores (menos tokens no contexto do LLM) e considere um cache de respostas para queries frequentes usando DynamoDB com TTL.
Decisões-chave e o caminho à frente
RAG não é uma tecnologia única, mas sim uma arquitetura composta por decisões independentes que se acumulam: estratégia de chunking, modelo de embedding, vector store, estratégia de retrieval e modelo de geração. Cada decisão tem trade-offs de custo, latência e qualidade, e o impacto de cada uma só pode ser medido com métricas adequadas.
Na AWS, a combinação Bedrock Knowledge Bases + S3 Vectors + Titan Embeddings V2 é o ponto de partida mais rápido para times que estão começando ou validando casos de uso. Para sistemas em produção com requisitos mais exigentes, a combinação OpenSearch Serverless com hybrid search + re-ranking + Bedrock Guardrails representa o estado da arte disponível hoje.
O diferencial entre um RAG mediano e um excelente não está na escolha do LLM, está na qualidade dos dados ingeridos, na granularidade do chunking e na robustez do pipeline de retrieval. Um sistema com dados bem preparados e retrieval preciso supera um sistema com o modelo mais caro e retrieval negligenciado.
A avaliação contínua com RAGAS fecha o ciclo e é o que transforma otimização de "tentativa e erro" em engenharia: cada decisão arquitetural pode ser validada antes de ir para produção, e regressões são detectadas antes de chegarem ao usuário.