Introdução de Negócio
Cada vez mais empresas utilizam machine learning para gerar vantagem competitiva, seja para prever demanda, detectar fraudes ou personalizar experiências digitais. No entanto, muitas organizações ainda enfrentam dificuldades para transformar experimentos de ciência de dados em soluções confiáveis em produção. Modelos desenvolvidos em ambientes experimentais frequentemente não possuem processos estruturados de treinamento, validação, deploy e monitoramento, o que limita sua escalabilidade e reduz o retorno sobre investimentos em inteligência artificial. Além disso, a falta de atualização constante de modelos causa erros por data drift, prejudicando sistemas em produção.
O que queremos resolver
O desenvolvimento de modelos de machine learning envolve múltiplas etapas, incluindo modelagem de dados, treinamento, ajuste de hiperparâmetros, testes e implantação. Sem uma esteira estruturada de MLOps, essas etapas acabam sendo executadas de forma manual ou pouco integrada.
Esse cenário cria desafios importantes para as organizações:
Além disso, muitas empresas precisam integrar modelos com sistemas corporativos existentes, garantindo baixa latência e segurança no acesso aos dados. Finalmente, a atualização manual de modelos com novos dados pode consumir tempo desnecessariamente além de ocupar profissionais qualificados que poderiam estar desenvolvendo novos modelos.
Como resolver na AWS
Uma arquitetura de MLOps na AWS permite estruturar todo o ciclo de vida de modelos de machine learning de forma automatizada e escalável.
O processo começa com os dados armazenados em uma estrutura própria, como um data lake central. Os dados são ingeridos para uma pasta Raw Data dentro do pipeline de MLOps para que o dado original seja persistido e resultados sejam reproduzidos com facilidade.
A preparação e transformação dos dados pode ser executada através de Amazon SageMaker utilizando processing jobs, que estruturam os dados para treinamento, modelando o mesmo e garantindo que o seu formato é compatível com o modelo escolhido.
Em seguida, pipelines automatizados realizam a otimização de hiperparâmetros e treinamento de modelos, permitindo testar múltiplas configurações e identificar o modelo com melhor desempenho. Para isso, o Amazon SageMaker HPO e Training Job podem ser utilizados para automatizar essa busca de hiperparâmetros ótimos.
Após o treinamento, os modelos gerados são armazenados como artefatos no Amazon S3 e passam por etapas de validação, incluindo testes em batch utilizando SageMaker Batch Transform.
Uma vez aprovados, os modelos podem ser disponibilizados através de endpoints serverless do SageMaker, permitindo que aplicações corporativas consumam inferências em tempo real em uma estrutura altamente escalável e custo-efetiva.
As chamadas para inferência podem ser processadas por AWS Lambda, que integra o endpoint do modelo com APIs corporativas expostas via API Gateway. Resultados das inferências podem ser armazenados em Amazon DynamoDB, permitindo análises posteriores e auditoria.
Toda a orquestração dessa esteira é realizada com AWS Step Functions, garantindo automação do pipeline completo de machine learning.
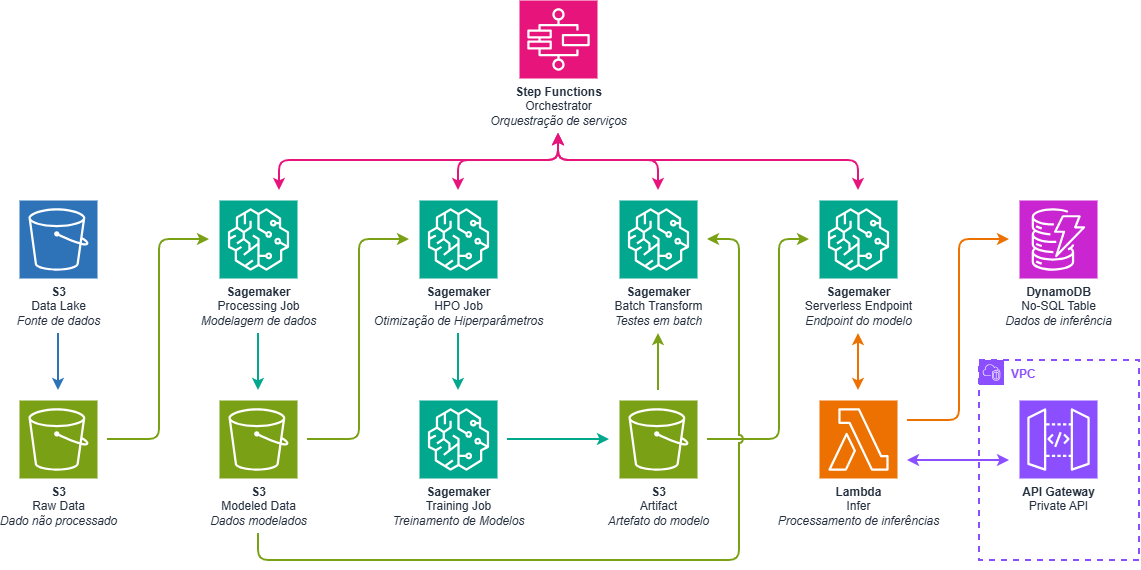
A figura acima representa de forma simplificada essa arquitetura AWS para a solução de MLOps AWS.
Ganhos que a arquitetura traz
Automação do ciclo de vida de modelos: Pipelines automatizados reduzem o tempo necessário para treinar, validar e implantar modelos, prevenindo data drift e garantindo que profissionais de ciência de dados usem o seu valioso tempo em novas iniciativas.
Reprodutibilidade de experimentos: Cada etapa do pipeline é versionada e controlada, permitindo replicar resultados com facilidade. Isso protege o seu modelo de um cenário de viés de treinamento que pode prejudicar estruturas em produção.
Escalabilidade para inferências: Endpoints serverless permitem atender grandes volumes de requisições sem gerenciamento de infraestrutura. Tudo em um modelo "pay as you go", onde tempo de ociosidade de modelos não gera uma cobrança desnecessária.
Integração com aplicações corporativas: APIs e funções serverless permitem que sistemas internos consumam modelos de forma simples e segura.
Base para governança de IA: A arquitetura facilita auditoria de modelos, rastreabilidade de dados e monitoramento de performance.
Casos na literatura
A adoção de práticas estruturadas de MLOps pode acelerar significativamente o ciclo de desenvolvimento de soluções de inteligência artificial. Um estudo publicado pela Google Research e Stanford mostrou que o uso de ferramentas de IA para apoiar operações de suporte pode aumentar a produtividade dos agentes em cerca de 14%, demonstrando o impacto direto de sistemas baseados em modelos em ambientes produtivos.
A adoção de práticas estruturadas de MLOps permite aumentar significativamente a taxa de sucesso de iniciativas de inteligência artificial. Segundo a Gartner, até 30% dos projetos de IA generativa são abandonados após a fase de prova de conceito, principalmente devido à baixa qualidade dos dados, falta de governança e dificuldades de operacionalização em produção. Esses desafios reforçam a importância de pipelines estruturados de dados e modelos, capazes de automatizar treinamento, validação e implantação de modelos em escala.
A adoção de práticas estruturadas de MLOps permite escalar o uso de machine learning dentro das organizações, reduzindo o tempo necessário para levar modelos de experimentação para produção. Um exemplo disso é o caso do banco NatWest, que construiu uma plataforma de MLOps baseada em Amazon SageMaker para padronizar e automatizar o ciclo de vida de modelos. Com essa abordagem, a organização conseguiu criar um ambiente escalável e seguro para centenas de cientistas de dados desenvolverem e implantarem modelos de forma mais rápida e reproduzível.
Outro exemplo é a empresa EagleView, que migrou seus pipelines de machine learning para Amazon SageMaker para lidar com grandes volumes de imagens e workloads de inferência. Após a adoção da arquitetura baseada em SageMaker, a empresa reduziu o tempo de processamento de imagens de 16 horas para cerca de 1,5 hora, além de obter melhorias de 300 a 400% na performance dos modelos e maior confiabilidade para suportar cargas de inferência em escala.
Lições aprendidas
A implementação de uma esteira de MLOps na AWS permite transformar projetos de machine learning em sistemas robustos e escaláveis. Ao combinar armazenamento de dados, pipelines de treinamento automatizados, endpoints de inferência e orquestração de workflows, empresas conseguem reduzir o tempo entre experimentação e produção. Essa abordagem cria uma base sólida para expandir o uso de inteligência artificial, permitindo que organizações inovem com mais velocidade e segurança em suas iniciativas de dados e analytics.